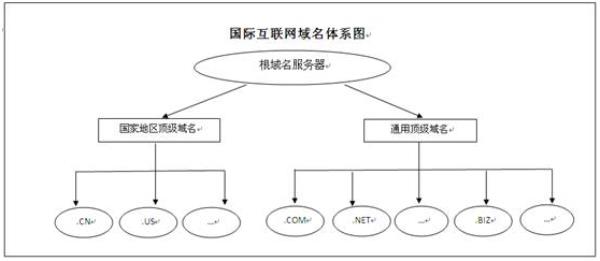
如何用python爬取网站数据?
用python爬取网站数据方法步骤如下:首先要明确想要爬取的目标。对于网页源信息的爬取首先要获取url,然后定位的目标内容。先使用基础for循环生成的url信息。
插图")
selenium是一个自动化测试工具,也可以用来模拟浏览器行为进行网页数据抓取。使用selenium库可以执行JavaScript代码、模拟点击按钮、填写表单等操作。
安装必要的库 为了编写爬虫,你需要安装一些Python库,例如requests、BeautifulSoup和lxml等。你可以使用pip install命令来安装这些库。抓取网页数据 主要通过requests库发送HTTP请求,获取网页响应的HTML内容。
我们创建一个爬虫,递归地遍历每个网站,只收集那些网站页面上的数据。
模拟请求网页。模拟浏览器,打开目标网站。获取数据。打开网站之后,就可以自动化的获取我们所需要的网站数据。保存数据。拿到数据之后,需要持久化到本地文件或者数据库等存储设备中。
python是一款应用非常广泛的脚本程序语言,谷歌公司的网页就是用python编写。python在生物信息、统计、网页制作、计算等多个领域都体现出了强大的功能。
如何用python实现网络爬虫
使用Python编写网络爬虫程序的一般步骤如下: 导入所需的库:使用import语句导入所需的库,如BeautifulSoup、Scrapy和Requests等。 发送HTTP请求:使用Requests库发送HTTP请求,获取网页的HTML源代码。
首先要明确想要爬取的目标。对于网页源信息的爬取首先要获取url,然后定位的目标内容。先使用基础for循环生成的url信息。然后需要模拟浏览器的请求(使用request.get(url)),获取目标网页的源代码信息(req.text)。
一般来说,编写网络爬虫需要以下几个步骤: 确定目标网站:首先需要确定要抓取数据的目标网站,了解该网站的结构和数据存储方式。
三行 网络爬虫是指通过自动化程序去获取互联网上的信息和数据,一般需要使用编程语言来实现。在 Python 中,使用第三方库 requests 和 BeautifulSoup 可以很轻松地实现一个简单的网络爬虫。
考虑如何用python实现:在各台slave上装好scrapy,那么各台机子就变成了一台有抓取能力的slave,在master上装好Redis和rq用作分布式队列。
推荐使用Requests + BeautifulSoup框架来写爬虫,Requests用来发送各种请求,BeautifulSoup用来解析页面内容,提取数据。当然Python也有一些现成的爬虫库,例如Scrapy,pyspider等。
如何用Python爬虫抓取网页内容?
1、以下是使用Python3进行新闻网站爬取的一般步骤: 导入所需的库,如requests、BeautifulSoup等。 使用requests库发送HTTP请求,获取新闻网站的HTML源代码。 使用BeautifulSoup库解析HTML源代码,提取所需的新闻数据。
2、使用requests库获取网页内容 requests是一个功能强大且易于使用的HTTP库,可以用来发送HTTP请求并获取网页内容。
3、安装必要的库 为了编写爬虫,你需要安装一些Python库,例如requests、BeautifulSoup和lxml等。你可以使用pip install命令来安装这些库。抓取网页数据 主要通过requests库发送HTTP请求,获取网页响应的HTML内容。
4、用python爬取网站数据方法步骤如下:首先要明确想要爬取的目标。对于网页源信息的爬取首先要获取url,然后定位的目标内容。先使用基础for循环生成的url信息。
5、“我去图书馆”抢座助手,借助python实现自动抢座。在使用“我去图书馆”公众号进行抢座的时候,在进行抢座前我们都会进入一个页面,选定要选的座位之后点击抢座。
Python爬虫如何写?
)首先你要明白爬虫怎样工作。想象你是一只蜘蛛,现在你被放到了互联“网”上。那么,你需要把所有的网页都看一遍。怎么办呢?没问题呀,你就随便从某个地方开始,比如说人民日报的首页,这个叫initial pages,用$表示吧。
安装必要的库 为了编写爬虫,你需要安装一些Python库,例如requests、BeautifulSoup和lxml等。你可以使用pip install命令来安装这些库。抓取网页数据 主要通过requests库发送HTTP请求,获取网页响应的HTML内容。
利用python写爬虫程序的方法:先分析网站内容,红色部分即是网站文章内容div。
目前最适合用于写爬虫的语言是python,python中最受欢迎的爬虫框架是scrapy,本文围绕scrapy来展开讲解爬虫是怎么工作的。
如何用Python编写一个简单的爬虫
1、使用Python编写网络爬虫程序的一般步骤如下: 导入所需的库:使用import语句导入所需的库,如BeautifulSoup、Scrapy和Requests等。 发送HTTP请求:使用Requests库发送HTTP请求,获取网页的HTML源代码。
2、安装必要的库 为了编写爬虫,你需要安装一些Python库,例如requests、BeautifulSoup和lxml等。你可以使用pip install命令来安装这些库。抓取网页数据 主要通过requests库发送HTTP请求,获取网页响应的HTML内容。
3、)首先你要明白爬虫怎样工作。想象你是一只蜘蛛,现在你被放到了互联“网”上。那么,你需要把所有的网页都看一遍。怎么办呢?没问题呀,你就随便从某个地方开始,比如说人民日报的首页,这个叫initial pages,用$表示吧。
4、利用python写爬虫程序的方法:先分析网站内容,红色部分即是网站文章内容div。
以上就是python简单爬虫代码(python 爬虫 代码)的内容,你可能还会喜欢python简单爬虫代码,互联网,网页,url等相关信息。